



Introducing: Multimodal Application Platform

The time to introduce multimodal AI is Now!
Welcome to the visually driven world we live in today, where images and videos are not just components of our daily lives but crucial elements in decision-making processes. Whether it's choosing products online, exploring potential homes, or seeking personalized video content, visual information guides our choices. In an era dominated by structured data and textual documents, the question arises: how to harness the rich potential of visual content?
Today's technological advancements unlock the immense value hidden within visuals, be it company assets, user or machine-generated content. What was once mere pixels is now a treasure trove of actionable insights and opportunities.
However, integrating AI solutions for visual data into your application might seem daunting. Do you need to dive deep into the complexities of machine learning or hire a specialized team to handle the massive data flow?
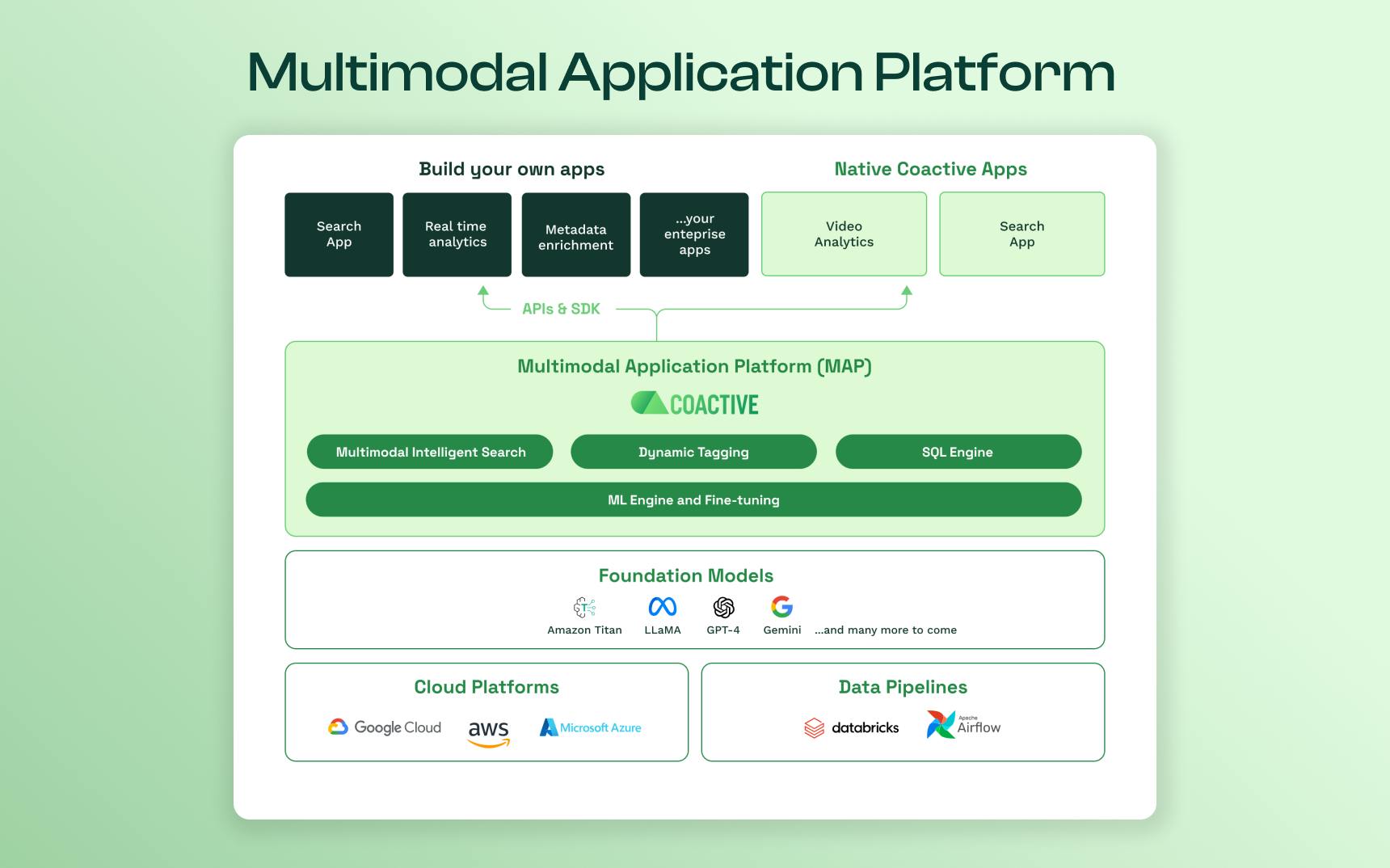
Coactive’s Multimodal Application Platform (MAP) takes this complexity off your plate. We provide a turnkey AI platform to work with images and videos and build applications on top of that. We are transforming what used to be an AI challenge into a manageable engineering problem.
Why do you need a Multimodal Application Platform?
Let’s examine in detail what it takes to build an application that uses multimodal ML. We can divide the necessary work into three parts: Infrastructure, Data preprocessing, and ML workflow. Spoiler alert: You can eliminate this complexity with Coactive’s turnkey platform, allowing you to focus squarely on your application’s development.
The Hidden Complexity of an AI Application

Infrastructure. You must prepare for the large volume of data processing and ML with the necessary infrastructure. For example, to process a video archive of hundreds of videos, you would need to have a streaming architecture and manage multiple tools. Although you might be somewhat familiar with this part as they have built applications, now you need to add ML-specific components, such as a vector database needed for efficiently storing and comparing billions of embeddings.
Data Preprocessing. ML requires preprocessing of the data. Current out-of-the-box multimodal foundation models do not support video. You would have to extract specific frames from each video before you can do any manipulation. Selecting the right frame is a challenge in itself that also has to be analyzed: How do you know that the frame has the key moment that you are trying to analyze? How can an ML differentiate between a rolling ball and a ball lying still?
Can you tell if the ball is rolling based on a single frame?

ML Workflow. Lastly, you need to deploy one of the foundation models. There are many open-source and closed-source models available, but which one should you choose? How should you evaluate the trade-offs between the models? More importantly, if a better model becomes available, do you need to re-do your implementation to switch the models? Additionally, standard foundation models may require fine-tuning to understand your company’s context, which is a challenge in itself.
Coactive’s Multimodal Application Platform provides a turnkey solution for all the challenges. And you do not need a specialized team of ML engineers to get started. We take on the infrastructure complexity of working with multimodal ML & advanced data preprocessing. For example, when working with videos, we evaluate which frames are the most relevant and combine multiple frames to identify dynamic actions. As for the foundation models, Coactive allows you to use a range of open-source and closed-source models. You can easily compare the performance of those models on your data and switch to a newer model at any moment.
Simply use our APIs or SDK, and you will have the power of multimodal AI at your fingertips.
Customization and fine-tuning
Out-of-the-box foundation models are powerful, but they lack customer-specific context. How do you define your own taxonomy and meanings? What if the images and videos you are working with are not in the public domain? The standard foundation models were not trained on them, and do not understand them well.
The challenge then becomes how to customize these models to understand your specific taxonomy and semantics. Traditional fine-tuning methods are not only complex but also costly. They typically involve retraining the entire model, which can have billions of parameters, on a new set of data tailored to your needs.
Coactive's approach simplifies this process. Our platform allows you to use dynamic tags to introduce new concepts, specific terminology, and even unique taxonomy to the foundation models. For instance, within a minute, you can teach Coactive about new industry-specific terms, local slang, or even a newly created cartoon character. These dynamic tags utilize the underlying embeddings from the foundation model to deliver highly accurate results, bypassing the need for extensive machine learning training.
Read more about the customization of the multimodal AI in our future blog posts. We'll dive deeper into how these adaptations can transform your applications and streamline your operations.
What can you do with the Multimodal Application Platform?
The sky is the limit. Here are just a few examples of how our customers are already harnessing the power of this technology:
Visual Search. Search through the product catalog or internal archive of images and videos in seconds. With multimodal AI, you don’t need metadata or documentation to find what you are looking for. Searching for “White shoes with red stripes” or “John jumping off a cliff on a motorcycle” will give your users the perfect match of a product from your catalog or a specific moment from your entire video archive.
Intelligent Search
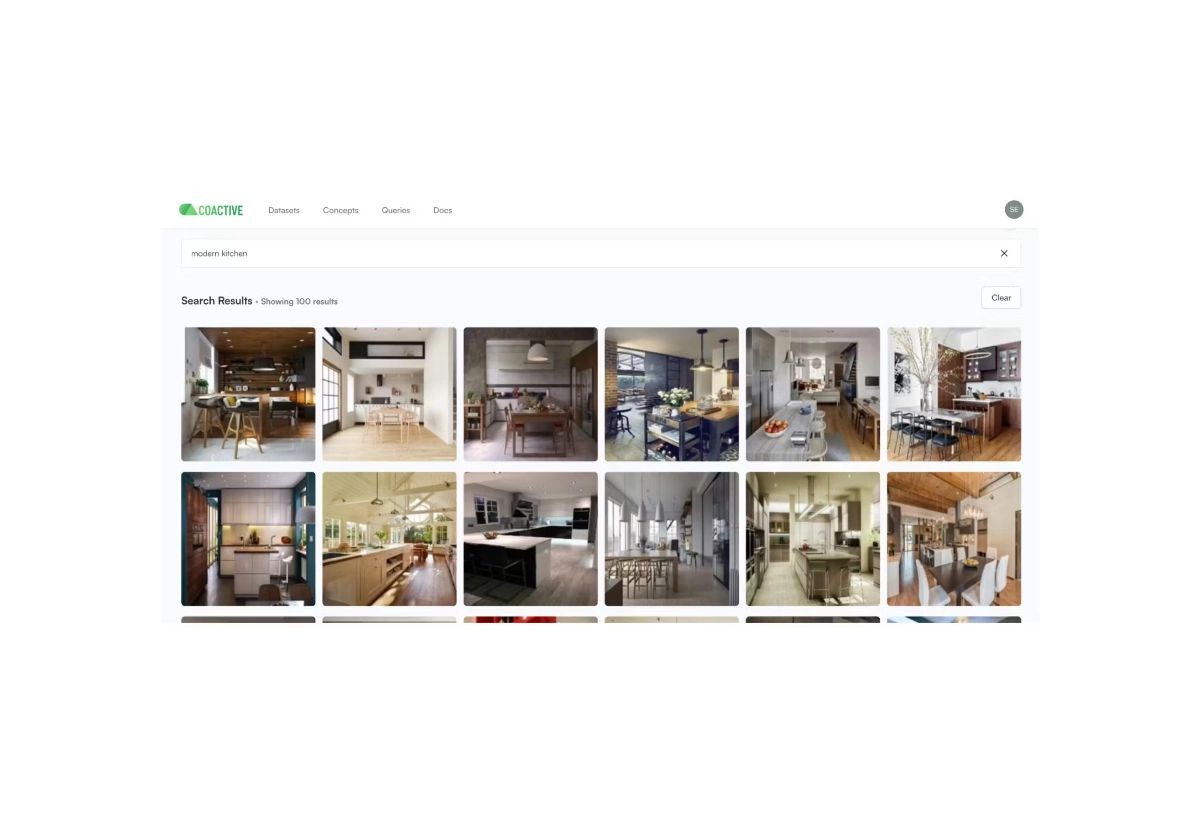
Read more about the Intelligence Search here.
No metadata? no problem! With Coactive, you can understand your content like never before. Our platform lets you ‘extract’ metadata from the visual content itself. For example, you can identify categories and attributes for individual items in your catalog, categorize your products and user-generated images, or generate metadata for a video archive. With the metadata based on the visual content, the use cases range from personalization to advertisement.
Visual Analytics. Derive valuable insights from your data through advanced business analytics. Want to identify current trends? Interested in understanding which types of visual content resonate most on your platform? Our platform provides the tools to analyze these trends and more, helping you make informed decisions.
We can only imagine what you can build with multimodal AI. With Coactive’s Multimodal Application Platform, you can focus on your solutions and users while we handle the complexity of the AI implementation.


